Project Naptha RU – распознавание текста на любых картинках и фотографиях (в том числе и локальных) с помощью локального JS-движка Ocrad (только английский язык) или посредством бесплатного облачного OCR-сервиса Tesseract: 9 языков (включая русский). Готовый текст можно выделить и скопировать, выполнить по нему поиск или перевести его на другой язык. Предоставляется по лицензии GPL v.3, бесплатно для частного некоммерческого использования.
В этой статье:
Project Naptha RU – расширение для браузеров семейства Chromium, позволяет оперативно распознать и скопировать текст на любом изображении, включая локальные файлы.
Основное назначение – автоматическое распознавание текста, представленного в графическом виде, это настоящая система OCR, работающая только за счёт ресурсов браузера. Главная задача – убрать "ручной труд" по набору текста, "всеядность" и компактность решения.
Расширение создано по мотивам и на базе расширения Project Naptha. В русском форке оставлен основной код оригинала, удалены "полурабочие" функции, а также добавлены некоторые дополнительные возможности и полностью русифицирован интерфейс.
В результате "доработки напильником" русский форк аддона стал хорошей альтернативой аналогам, не только не уступая им по качеству решения основной задачи, но и превосходя их по общему функционалу.
Следует особо отметить, что в отличие от многих современных аддонов, в Project Naptha RU нет (и никогда не будет) никакой "допустимой" или скрытой рекламы, расширение не является предметом монетизации за счёт пользователей.
Автор гарантирует отсутствие в этом расширении каких-либо следящих, "стучащих" и иных "статистических" механизмов, а также любых других средств, направленных на "персонализацию" конечного пользователя с целью получения какой-то коммерческой выгоды.
Project Naptha RU работает как OCR на базе локального JS-движка или облачного сервиса. Общее описание функций и демонстрация основных возможностей доступны на официальном сайте оригинального проекта (на английском языке).
Расширение не требует от пользователя никаких действий для активации распознавания, фоновый скрипт начинает работать автоматически при помещении курсора мыши поверх любого изображения на просматриваемой странице.
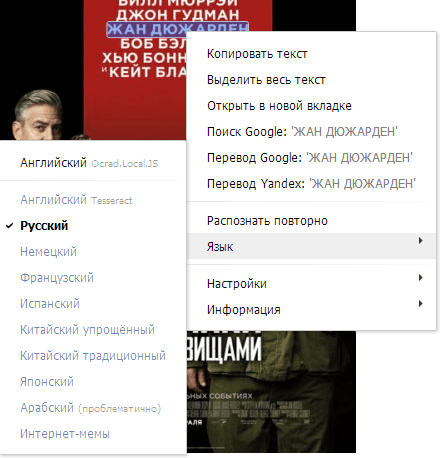
При этом по щелчку правой кнопкой мыши на любом изображении появляется меню доступных действий:
[Копия скриншота]
Project Naptha RU умеет распознавать текста на любых (в т.ч. и локальных) картинках и фотографиях с помощью локального JS-движка Ocrad либо посредством бесплатного облачного OCR-сервиса Tesseract.
Локальный движок OCR "понимает" только английский язык, внешний сервис позволяет распознавать 9 языков (включая русский) + специальное распознавание интернет-мемов.
Предупреждение: Основной скрипт локального OCR-движка достаточно ресурсоёмкий, поэтому на слабых компьютерах аддон лучше включать только по необходимости, чтобы обработка изображений не начиналась при помещении курсора мыши поверх любой картинки на всех просматриваемых страницах, что, соответственно, будет приводить к серьёзному торможению* сёрфинга.
* Во избежание ненужных "а почему" и "какого лешего" – берегите нервы… …и не говорите, что вас не предупредили… х)
Любой распознанный на изображении текст можно выделять и копировать. Кроме того, в русской версии доступны некоторые дополнительные функции, расширяющие возможности работы с полученным тексттом.
Все отличия указаны для текущей версии Project Naptha RU, в более старых часть добавленных функций отсутствует.
Русский форк проекта работает с изображениями на любых страницах, в том числе – на локальных.
Язык интерфейса – только русский (локализация жёсткая, зашита в коде), другие* локализации отсутствуют. Это связано со значительным упрощением кода и повышением скорости его работы, а также с тем, что при создании расширения автор в первую очередь ориентируется на русскоязычных пользователей.
* Впрочем, если "дело пойдёт", прикрутить ещё и "басурманский" не является особой проблемой…
Начиная с версии 2014.5.2 (оригинал – 0.7.8) введён поиск в Google* выделенного фрагмента распознанного текста.
* Можно было бы прикрутить и любой другой, но особого смысла в этом автор не увидел…)
В исходном расширении заявлена фича перевода, которая может быть задействована только при прямом обращении к автору по почте, поэтому в русском форке она удалена из меню. Вместо этого, начиная с версии 2014.5.2, в русском форке подключены переводчики* Google/Yandex (язык и направление перевода определяются автоматически).
* Прямой вызов, открываются в отдельном окне, без задействования API перевода браузера.
В русском форке также отключены и удалены из меню и другие демо-фичи, не работающие на реальных веб-страницах, как то – удаление и замена текста, включение/выключение распознавания на отдельных страницах/сайтах, также убрана озвучка* выделенного текста (введена в оригинале с версии 0.7.7).
* С английским ещё куда ни шло, но русский и другие просто невозможно слушать… :/
Исходный код расширения НЕ обфусцирован, все демо-функции отключены простым закомментариванием в исходнике, поэтому желающие (и умеющие)) могут самостоятельно включить обратно все отключённые функции путём ручной правки* исходного кода JS.
* В принципе, там всё прозрачно и понятно, спасибо автору за хорошую документированность скриптов…))
Чтобы распознать текст на картинке нужно просто навести курсор мыши на изображение и подождать*, пока аддон обработает его. При этом курсор мыши, расположенный над текстом, изменится со стандартной "стрелки" на вертикальный текстовый курсор.
* Определить, что скрипт работает, можно по увеличению загрузки процессора, которая снизится до обычной после окончания распознавания. Время ожидания сильно зависит от качества прорисовки и объёма текста на картинке и на медленных компьютерах этот процесс может занимать от нескольких секунд до минуты и более.
По окончанию процесса распознавания, нажав на тексте правую кнопку мыши, можно выбрать в появившемся контекстном меню аддона нужное действие – выделить, скопировать, перераспознать и т.д..
• Самое главное – помнить, что деда Мороза нет чудес не бывает… Поэтому если вы, как "хромо-сапиенс", и сами с трудом разбираете текст на мутной картинке-миниатюре (да ещё и со смазанным мелким текстом), то никакой халявный движок OCR уж тем более его не распознает…)
• Следовательно, самый первый совет – для максимально качественного и быстрого распознавания используйте самую лучшую из доступных картинок. В частности, если на веб-страницах есть увеличенные версии, используйте именно их для повышения качества распознавания.
• Чтобы проверить, насколько уверенно OCR "увидела" текст, можно выбрать в меню "Выделить всё", при этом сразу будут видны все блоки текста, определённые движком, и вы сможете предварительно оценить результат.
• Для того, чтобы в копируемый текст не добавлялось предупреждение об использовании локального JS-движка, в настройках аддона можно отключить пункт "Предупреждения OCR". Эта настройка игнорируется, если используется облачный OCR-сервис (дополнительные уведомления при этом в копируемый текст также не добавляются).
• Для более уверенного распознавания выберите в настройках онлайновый движок Tesseract. Особенно это относится к не-английскому тексту, так как локальный JS-движок Ocrad распознаёт только английский язык.
• Если вы знаете* язык текста, лучше указать его прямо в настройках и произвести повторное распознавание текста. При этом корректность идентификации блоков текста на картинке и их распознавания существенно повышается.
* Основные сложности в определении, наверное, возникнут только с китайским/японским языками… …ах да, кроме "палочек и ёлочек" ещё ведь и "петельки с крючочками" есть… в смысле – арабский…))
• Для достижения наилучших результатов желательно* обрабатывать картинку отдельно, т.е. НЕ на самой веб-странице источника. Для этого нажмите на нужном изображении правую кнопку мыши и выберите пункт "Открыть картинку в новой вкладке" (либо просто перетащите картинку мышью на панель вкладок).
* Причина проста – на многих сайтах "шибко умные" дизайнеры пытаются "защитить" изображения наложением прозрачных слоёв и/или другими методами. При этом скрипт обработки картинки может просто не увидеть её и, соответственно, не распознает на картинке текст.
Расширение не имеет практических ограничений по версии браузера, может использоваться на любых хром-браузерах версий 29+. Однако, с учётом различных "новшеств", вводимых производителями браузеров, следует предварительно ознакомиться с документацией на конкретный билд, который планируется установить – могут быть, так сказать, "некоторые нюансики" и их необходимо учитывать.)
Можно загрузить любую из версий Project Naptha RU на следующих ресурсах:
Настоятельно рекомендуется использовать текущую стабильную версию расширения. Более ранние выпуски можно устанавливать только в исследовательских целях для сравнительного анализа функций и возможностей аддона. Авторская поддержка предыдущих версий не осуществляется, претензии по возможным проблемам их эксплуатации не рассматриваются.
При возникновении сложностей с установкой читаем этот совет.
Для работы в режиме "инкогнито" в блоке аддона на странице chrome://extensions включаем опцию: Разрешить использование в режиме инкогнито [читать матчасть]
Для работы с локальными файлами в блоке аддона на странице chrome://extensions включаем опцию: Разрешить открывать файлы по ссылкам